DataGAN: Leveraging Synthetic Data for Self-Driving Vehicles
GANs haven’t really found their place in self-driving cars right now, especially with recent advances in simulation and the vast amounts of data that has been collected.
So far, more than $16 billion has been spent on self-driving research. What’s the problem? Self-driving is expensive? Why? Getting data and training these models are not only time-consuming but really expensive. You then also need to take into account the fact that Waymo’s spent more than 20 million miles on public roads for data gathering (talking about the amount of energy consumed is for a whole other article…)
What percentage of data is actually useful? Very minimal. Why? Most of the data is usually from “normal” driving scenes, not edge case scenarios such as car overtaking, parking, traffic, etc.
How do we solve that?
Generative adversarial networks. Focusing on road/scenes rather than edge case scenarios i.e. parking and overtaking. Being able to generate vasts amounts of self-driving data while not having to spend excessive amounts of capital gathering data can be crucial in self-driving deployment.
As an attempt to solve this problem, I’ve been focusing on building DataGAN out. Leveraging Generative Adversarial Networks to create self-driving data at scale is crucial. By emphasizing a focus on DCGANs, I’m focusing on creating high-quality self-driving images that can be used to train and improve the performance of computer vision models such as lane + object detection, and semantic segmentation.
The boxing match: generator vs discriminator
GANs, simply put, is essentially a type of unsupervised learning algorithm where a model learns to discover and learn patterns in its dataset in such a way that the model itself can create new, generative outputs that could look as real as the original dataset itself.
In a GAN, 2 neural networks constantly compete against each other. This can be described as:
- The generator: this is the model that creates your generative outputs. By taking in latent (random) noise, the generator is then able to upsample it to create realistic images.
- The discriminator: the main goal behind the discriminator is to determine whether the image, created by the generator, is real or fake. This is where the term “adversarial” comes from in GANs → the generator and discriminator compete to see whether the generator can create images that can fool the discriminator.

In a sense, GANs are also supervised. The discriminator is a perfect example of that when distinguishing between real and generated images where all images that are generated can be labelled as 0 while the dataset images that the generator is training on can be labelled as 1.
The goal with GANs would be to reach an equilibrium where your discriminator can no longer distinguish real images from fakes while having a generator that can create realistic images as if it was taken from the original dataset.
Think of a GAN like a boxing match: if one opponent is stronger than the other, one of the boxers will get destroyed. But if the boxers are even in strength, then they’ll continuously try to find a way to be better than one another (although it’s not possible, because they’re equally matched!).
This is the same thing with GANs: you want your generator and discriminator to be even in strength; having one stronger than the other will not allow for proper training (aka mode collapse). Instead, you want both of them to be equally strong, allowing some images to fool the discriminator while generating realistic images.
Since their introduction into Deep Learning in 2014, several extensions of GANs have been created, including Deep Convolutional GANs (DCGAN), Conditional GANs (CGAN), StyleGANs, and a lot more. DataGAN focuses on leveraging the use of DCGANs for creating its synthetic data.
Deep Convolutional Generative Adversarial Networks (DCGANs)
Rather than using straightforward Dense layers for generating + discriminating images, DCGANs leverage the use of Convolutional Neural Networks (CNNs) to accomplish this task. The TLDR; of CNNs is that Convolutional Neural Networks are essentially a method used to help break down images while capturing spatial + temporal dependencies an image has via its filters.
In a DCGAN, we would use upsampling techniques such as transpose convolutions and Leaky ReLU functions for the generator. On the other hand, we would use convolutions for downsampling the input until we get to a 1x1 output for the discriminator, therefore telling us if the input image is real or not.
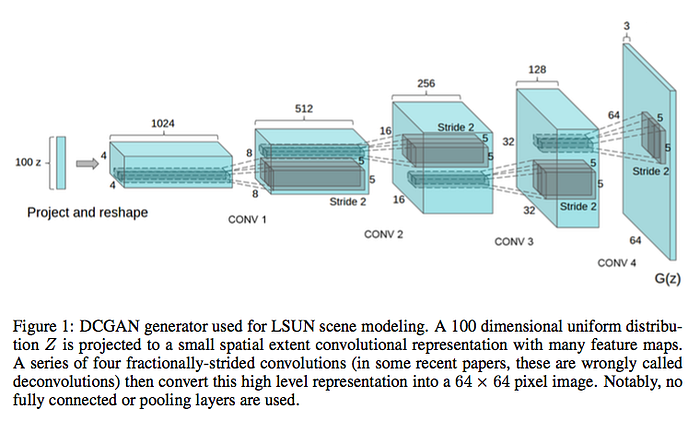
Some of the main differences between your Vanilla GAN and a DCGAN can be summarized as follows:
- Both networks (discriminator + generator) are Fully Convolutional Networks (FCN). What this means is that there are no Dense/maxpooling layers after convolutions.
- ReLU is used as the activation function for generators while LeakyReLU is used for the discriminator
- Batch normalization is now a method that’s consistently used to help with gradient flow and avoid vanishing/exploding gradient problems
- Tanh is the output function and should be used instead of something like sigmoid (normalization between [-1, 1] instead of [0, 1])
In the original GAN paper, the goal of the generator is to minimize the following function while the goal of the discriminator becomes to maximize it:
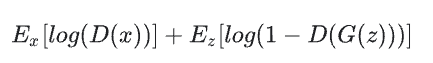
D(x) is the discriminator’s estimate of whether data x is real or not. The goal of the discriminator is to maximize this function i.e. output 1, for the true x data. For fake images, we want to ensure that D(G(z))’s [discriminator output from generator for input latent vector x] output is near 0.
Here’s what that means:
Let’s say that the discriminator outputs D(x)=0.99, D(G(z))=0.02:
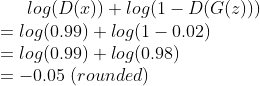
For context, log(1)+log(1)=0. Notice how that the discriminator’s practically maximized this function. It’s predicted that x is a real image while the generated image is not.
For the generator though, the goal will always be to maximize D(G(z)). This essentially means that we want the discriminator to always predict that the generated image is always real. The closer D(G(z)) is towards 1, the more realistic the discriminator thinks the generator is.
If the generator’s fooled the discriminator, then this is “assurance” that the way the generator is learning is right, which allows the model to continue training while producing high-quality images.
When dealing with our loss and optimization functions, we can generally use something like Adam along with a learning rate of 2e-4 (mentioned in DCGAN paper) can allow for more stable training. Another interesting thing to note is that the BigGAN paper has shown that making the learning rate smaller for the discriminator (i.e. 5e-5) also helps with training and does not result in immediate collapse.
The overall loss metric generally used for doing our backward pass + gradient update though would be Binary Cross-Entropy (BCE).
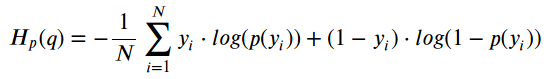
BCE essentially takes the negative average of the log of the predicted probabilities that were correct. For example, the closer D(x) is towards 1, the lower the loss function.
This is quite straightforward for the discriminator but what about the generator? For the generator, it would look like BCE(D(G(z)), 1). We want the discriminator output to be as close as it can be to 1 (indicating that it’s a real image). If we have a “perfect” generator, then our output values should always be close to 1.
DataGAN
DataGAN leverages the Fully Convolutional Network (FCN) architecture along with the Deep Convolutional Generative Adversarial Network to create trainable synthetic data.
With respect to training, I’m currently running DataGAN on a modified version of the Cityscapes Dataset. The quality and resolution of the dataset make it an ideal choice, especially considering the fact that generating urban scenes as opposed to highways, is a lot more beneficial for the overall AV industry.
For fast processing + training, I’m resizing the images to be 128x128 rather than the original 256x256 mainly because of hardware requirements.
My generator takes advantage of convolution transpose operations to help create realistic driving scene images while updating weights while training for robust outputs.
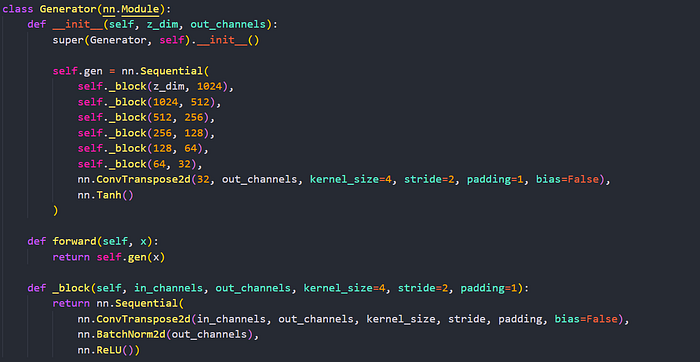
The generator is mainly structured around a finite amount of blocks, where each block consists of a Conv Transpose operation followed by a BatchNorm and ReLU layer. This allows the model to not only deal with the vanishing/exploding gradient problem but also have overall better stability + generalization when training the network.
The more features, the better it generally is. I also chose to implement the idea of a kernel size of 4 and a stride of 2, as implemented in the DCGAN paper. Additionally, the conv kernel bias is set to False, mainly because its impact is not noticeable as a result of the Batch Normalization layer.
ReLU has been shown throughout various papers and projects to work in the generator models but not the discriminator. Although Leaky ReLU might be helpful in some scenarios, it’s not and might even be redundant.
The goal generally is to have both a strong generator and discriminator and that doesn’t happen most of the time. What we’d have to do instead is make the discriminator a lot weaker.
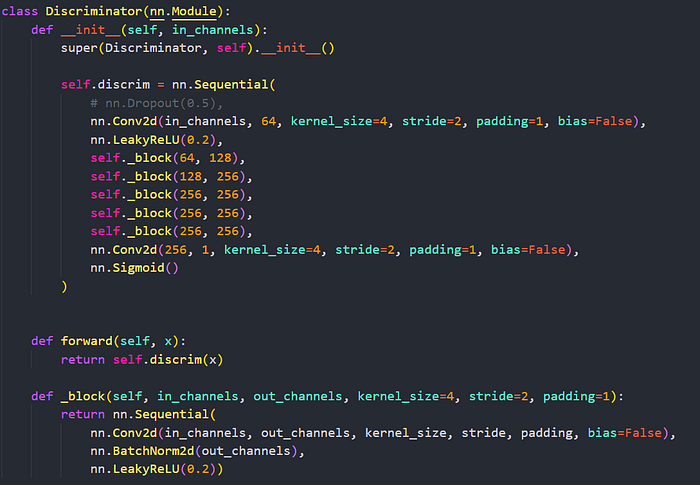
As seen, I’ve made the discriminator substantially weaker than my generator to allow for a more, balanced training.
Just as in the case of the generator, I’m following a similar structure with the conv blocks where I have a convolution followed by a batch normalization + leaky relu.
Throughout initial training, the biggest problem I noticed was the fact that the discriminator overpowered the generator, causing model collapse. In order to solve this, I initially introduced dropout (commented out) along with reducing the number of features substantially for smoother training.
We’ve seen that ReLU is used in the generator so why not in the discriminator as well? The problem with ReLU is that it can’t output negative gradients (anything <0). Therefore, this makes the network get stuck in a “dying state.”
What this means is that we’d essentially face a vanishing gradient problem where the discriminator produces only 0’s as the output. The generator is supposed to receive the gradient values from the discriminator, and if those values are simply 0’s, model collapse is certain to occur.
Leaky ReLU prevents that by allowing negative values to pass through which can be modified based on a hyperparameter, α (alpha). This will introduce tolerance in the network (which is where the idea of negative values passing through begins). In the case of DataGAN, I choose to follow through with the principles of the DCGAN paper → setting α to be 0.2, which has been proven successful in several models.
In the BigGAN paper, their findings show that having a bigger batch size allows for not only better generalization, but also for overall better performance. In my case, I chose to use a batch size of 64 as opposed to something like 128 or 256 because of how small my dataset is.
In order to ensure that the discriminator is weaker than the generator, I choose to set different learning rates for the models: for the generator, I have set the learning rate to 2e-4 while the discriminator uses a learning rate of
1e-5. The loss function used is standard Binary Cross-Entropy.
Current Progress
I’ve been training for around ~4000 (3875) epochs with this dataset (around 3075 images for training). Although I haven’t faced mode collapse (which is a good indicator so far!), here are some sample images for what it’s looking like.


Notice how the images have multiple, different types of buildings. And then lighting + structure of the lanes as well. This is data quite similar to that of real, road data, trained from my computer.
Why I built DataGAN
GAN’s haven’t really found their place in self-driving yet. With DataGAN, I propose a segway for the introduction of GANs in self-driving and show that they can play a vital role in generating synthetic data.
With recent advances in self-driving research, the main problem right now is deploying these vehicles at scale. Simulation research has been proven to play a huge role in LiDAR + camera research, but what if you can create real-world data without having to collect it yourself?
That’s the underlying goal of DataGAN → becoming so good at creating realistic driving scenes that one day, a full driving log can be made, just from GANs.
More updates soon on Github.
Next steps
Right now, due to hardware constraints, I’m focusing on generating scene images from DataGAN. Next steps/potential pathways right now could be summarized as followed:
- Build a straightforward lane detection model, fully trained on DataGAN outputs that are functional
- Create the first self-driving GAN dataset that can be used to train robust lane detection + computer vision models
- Make an AC-GAN model where you could potentially input an edge case scenario (ex. overtaking a vehicle) and use GAN-ConvLSTM to help generate the given scene
If this is a project that you’d like to collaborate and build, please send me an email! I’m always looking for collaborators along with lab resources, anything that you can do would be greatly appreciated.
Thanks for reading and learning more about what I’m building out. For more information about DataGAN, the code behind DataGAN can be found at its Github repository. If you’d like to build this out/inquire about DataGAN, here’s my Email, LinkedIn, Twitter, and Website. If you’d like to stay updated about DataGAN, you can add your email to my newsletter here.
